
관공서, 회사, 학교 등 여러 곳에서 수정이 불가능한 PDF 문서를 많이 쓰고 있습니다. 일반 워드, 엑셀 파일과 달리 PDF 파일은 편집이 불가능하여 안정성이 보장되므로 정식적인 문서, 보고서 등에 많이 쓰이고 있죠. 그래서 요즘은 PDF 편집 프로그램을 많이 사용하고 있는 분들이 많은 것 같습니다. 저도 최근 잘 사용하고 있는 원더쉐어사의 PDFelement를 사용하여 PDF 파일 사용시 꿀팁을 말씀드릴께요.
대학교나 대학원에서 논문이나 전공서적을 PDF파일로 넣어 편리하게 아이패드로 보시는 분들이 많으십니다. 이젠 무거운 전공서적을 맨날 가지고 다닐 필요도 없을 만큼 보관 및 휴대성이 좋아졌죠. 하지만 전자 파일이기 때문에 종이 책과 달리 정보를 한번에 쭉 넘겨가면서 서칭하는 것이 쉽지 않은 게 사실입니다. 그리고 한, 두 장이 아니라 문서의 양이 매우 많을 때는 더더욱 체력 소모를 많이 할 수밖에 없죠. 스캔한 파일은 보통 텍스트 인식이 전혀 되지 않고 바로 전체적인 이미지로 인식이 되기 때문에 손쉽게 <찾기>기능을 사용할 수도 없습니다. 그럴 때 사용할 수 있는 기능이 바로 OCR기능입니다. OCR이란 Optical Character Reader의 약자로서 한국어로는 광학 문자 인식이라고 불립니다. 이 기술을 이용하면 이미지나 스캔 과정을 거친 문서를 텍스트, 즉 문자로 손쉽게 변환되어 수정 및 편집도 가능하도록 이미지를 바꾸어 줍니다.
Step1. PDFelement <홈>에서 OCR기능으로 문자 인식을 하고자 하는 스캔 파일 PDF를 열어주세요.
그럼 파일이 불려오고 위쪽에 “스캔된 PDF임을 감지하고 스캔한 PDF 문서에서 텍스트를 복사, 편집 및 검색할 수 있는 OCR을 수행하는 것이 좋습니다.”라는 메시지가 뜨게 됩니다. 여기서 오른쪽에 있는 <OCR 수행>을 클릭해주세요. 처음 실행하시는 분은 OCR기능을 수행하기 위해 OCR에 필요한 부분을 추가적으로 다운로드해야 합니다.
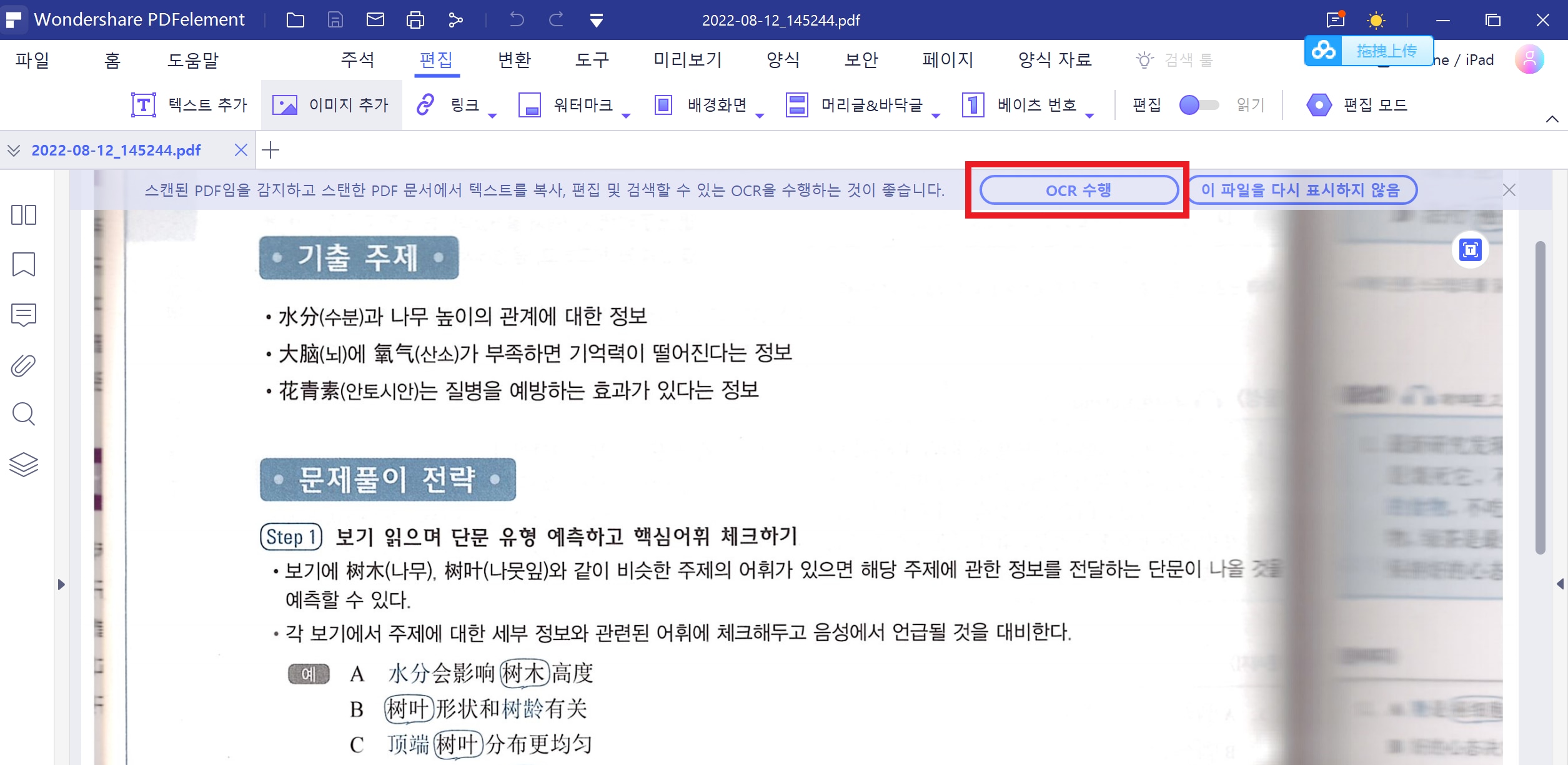
Step2. 모든 OCR기능을 다운로드 한 후 다시 <OCR 수행>버튼을 눌러주면 아래와 같이 옵션이 나타나게 됩니다.
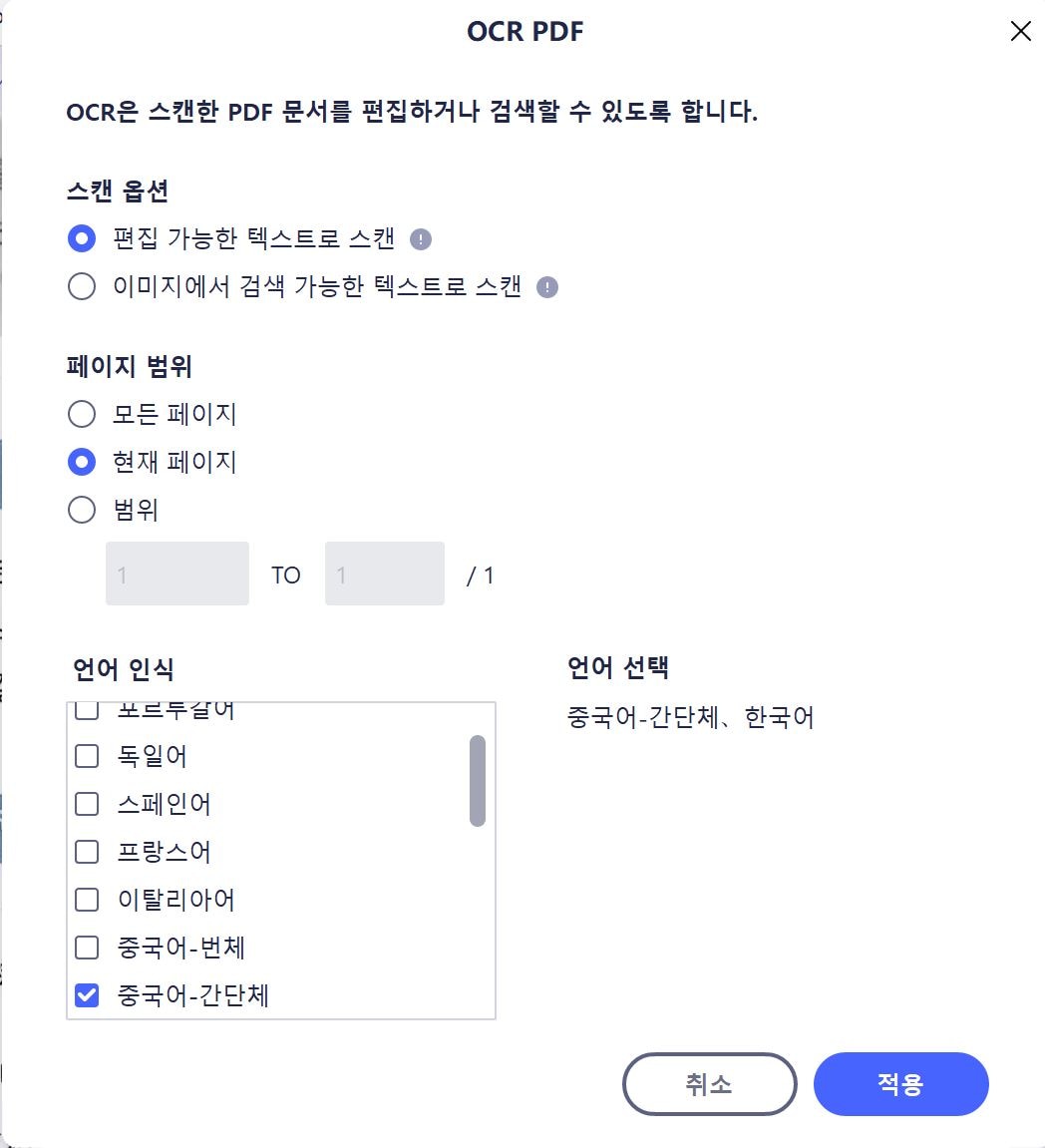
스캔 옵션은 총 두가지가 있는데, 첫번째는 OCR이 문자를 인식한 후 바로 편집이 가능한 텍스트로 스캔하는 것입니다. 두번째는 OCR이 문자를 인식하기는 하지만 편집 가능한 상태로 만드는 것이 아니라 검색만 가능하도록 만드는 방식입니다. PDF로 전자책을 만들어 사용하고자 하는 분들의 경우 밑줄이나 하이라이트 등을 표시할 수 있다면 추후 다시 전자책을 보더라도 중요한 부분을 빠르게 확인할 수 있겠죠. 그럴 때 첫번째 옵션을 선택하시면 됩니다. 페이지 범위는 모든 페이지 혹은 자기가 원하는 범위만 OCR 문자인식을 할 수도 있습니다. 그리고 언어는 보통 알아서 인식이 되기는 하는데, 추가해야 할 언어가 있다면 수동으로 클릭해주세요.
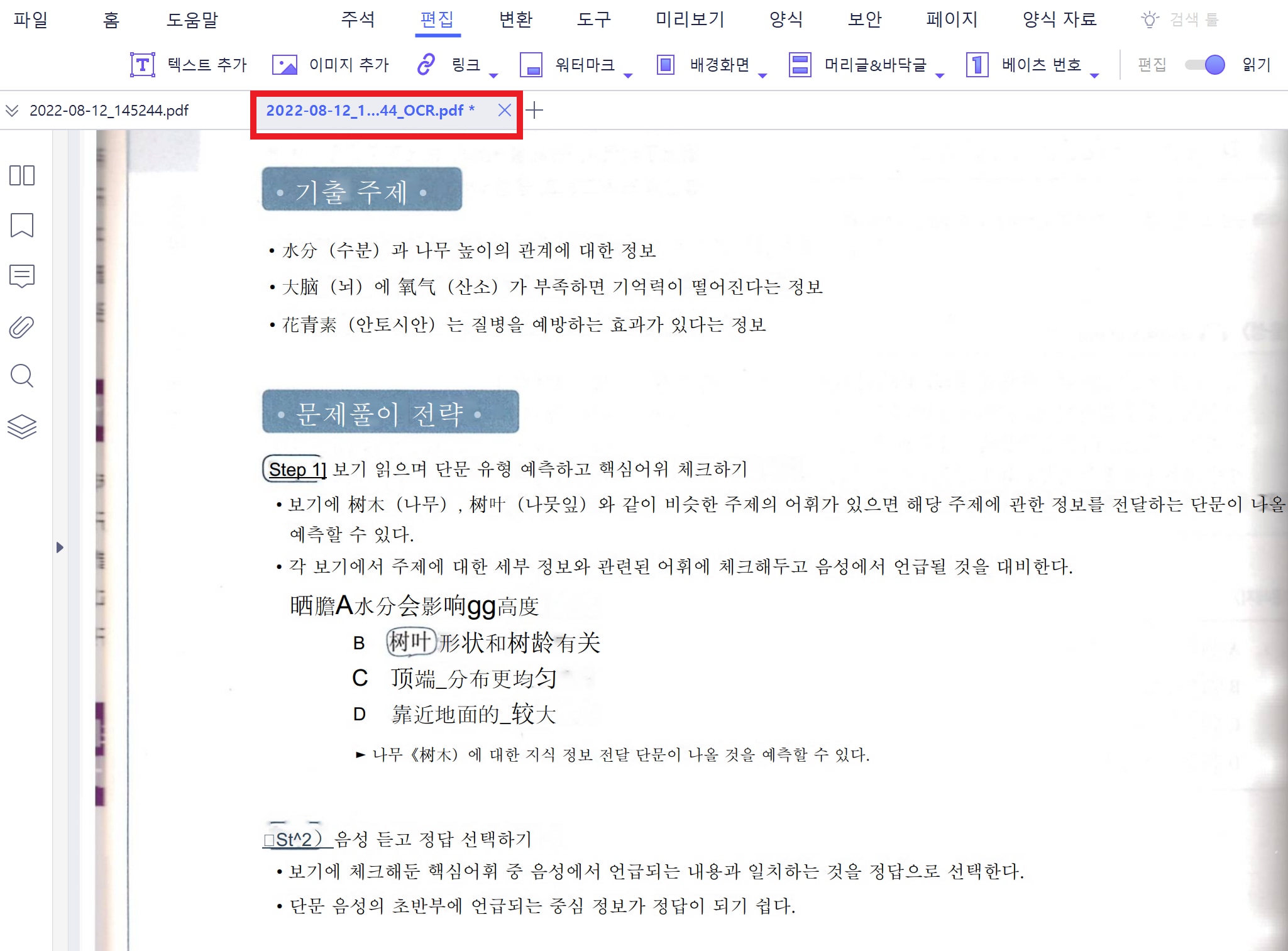
Step3. OCR을 실행하면 아래와 같이 OCR이 된 파일이 새 창에 나타나게 됩니다.
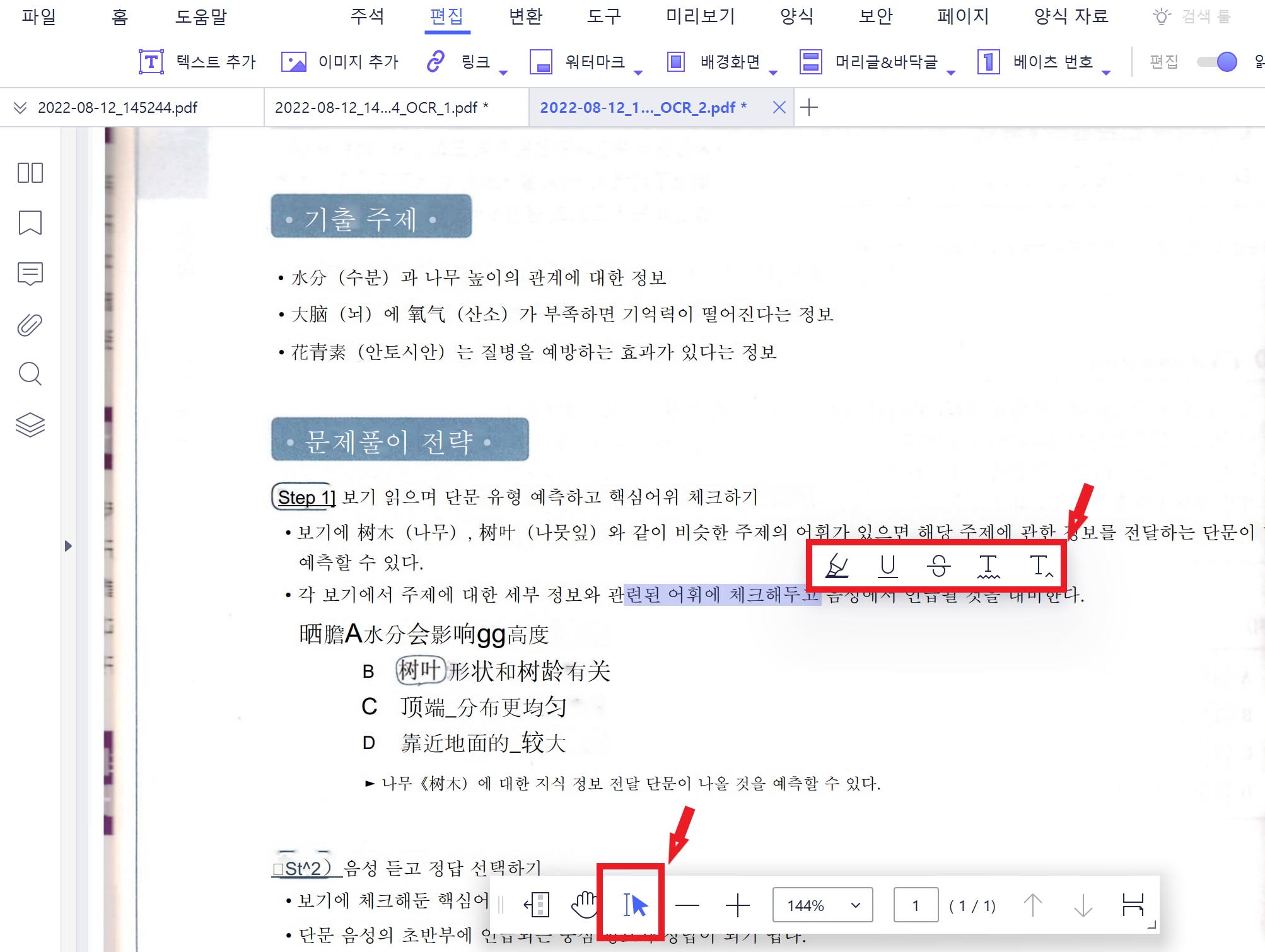
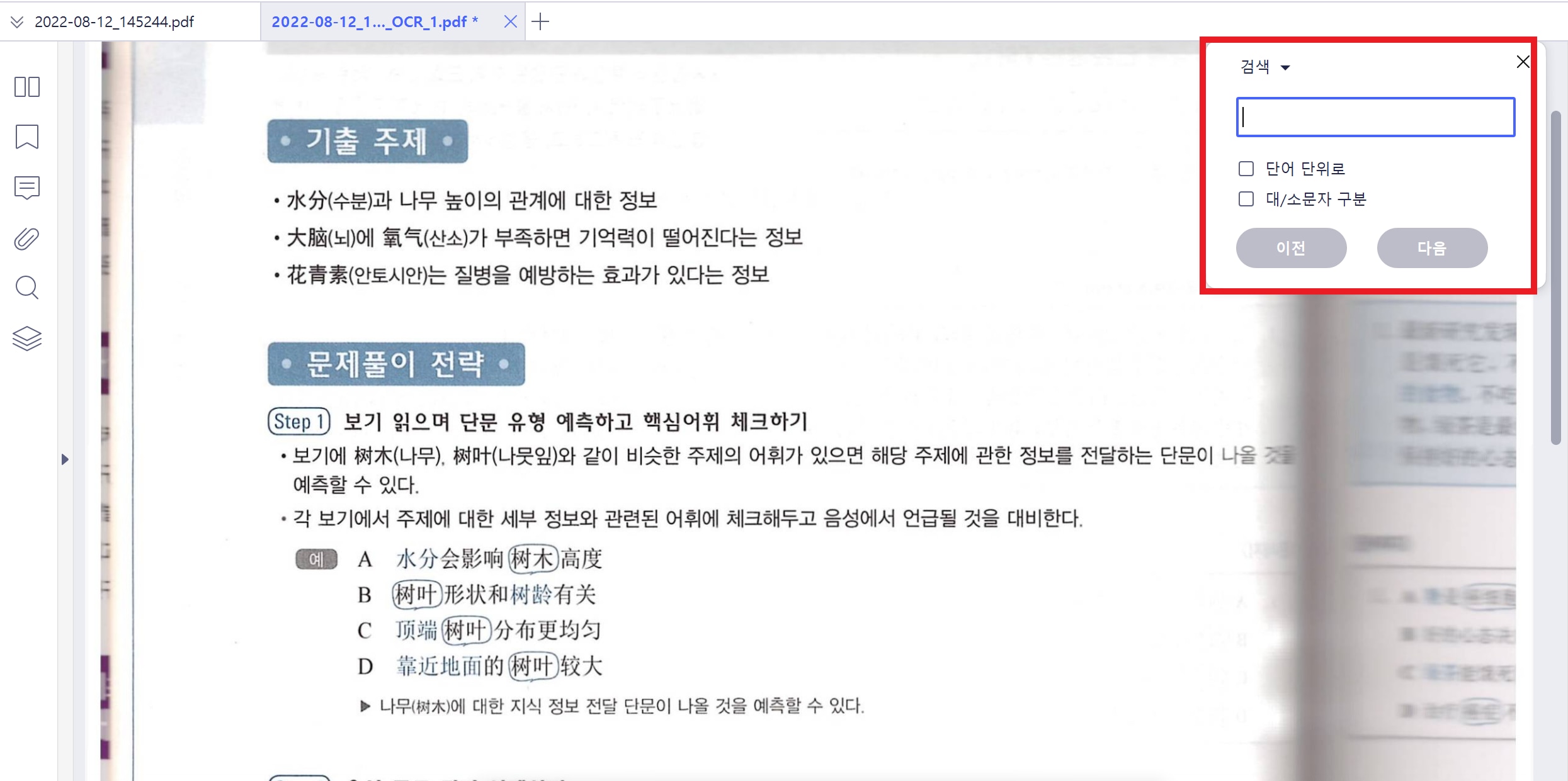
첫번째 옵션을 상세히 설명드리자면 OCR을 한 후에 마우스를 아래쪽으로 내리면 하단에 바가 나타나는데 여기서 마우스버튼을 클릭해주세요. 그런다음 본문을 마우스로 드래그하면 그 부분을 하이라이트, 밑줄, 취소선, 구불구불한 선등으로 표시할 수 있습니다. 특히 전공서적을 이렇게 PDF책으로 들고 다니시는 분들이시라면 아이패드로도 손쉽게 노트 필기를 하실 수 있을 거에요. 그리고 두번째 옵션을 선택하면 이렇게 편집기능은 나타나지 않고 대신 Ctrl+F버튼을 누르면 이렇게 검색창이 나타나는데 손쉽게 원하는 본문으로 이동이 가능할 것입니다.
PDFelement 프로그램은 윈도우, 맥 같은 PC뿐만이 아니라 아이패드, 스마트폰 같이 app환경에서도 사용이 가능합니다. PDFelement는 Adobe acrobat과 대비하여 가격은 저렴하면서도 깔끔한 디자인으로 거의 모든 pdf편집 기능을 제공하고 있어 회사원분들, 대학생분들에게도 모두 추천드리는 프로그램입니다. 우리 모두 스마트한 문서생활을 하도록 해요!