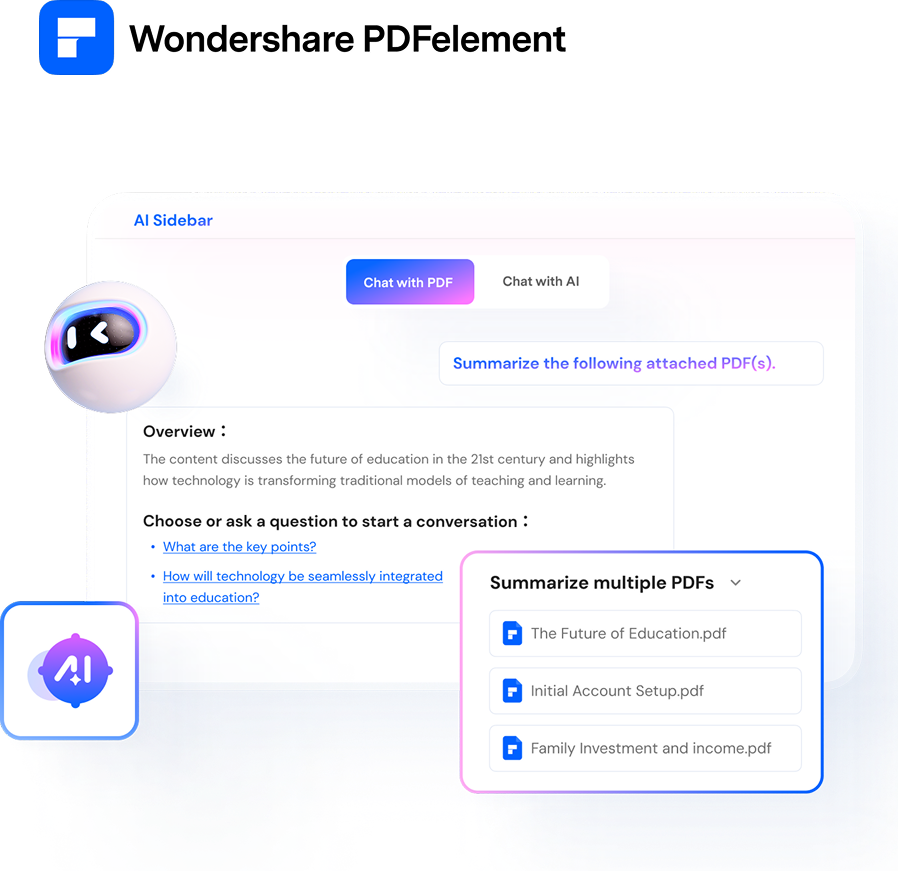









클릭 한 번으로 PDF 스캔하고
편집가능하며 HD 퀄리티로 검색 가능한 파일로 변경
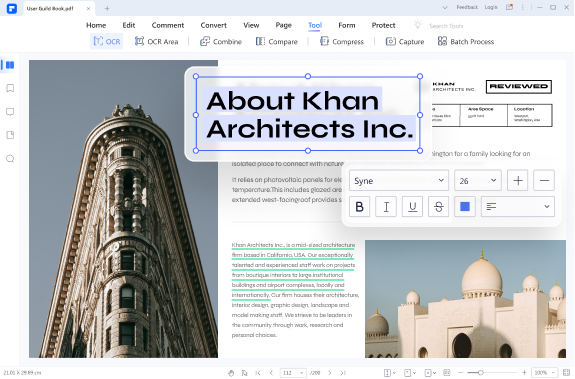
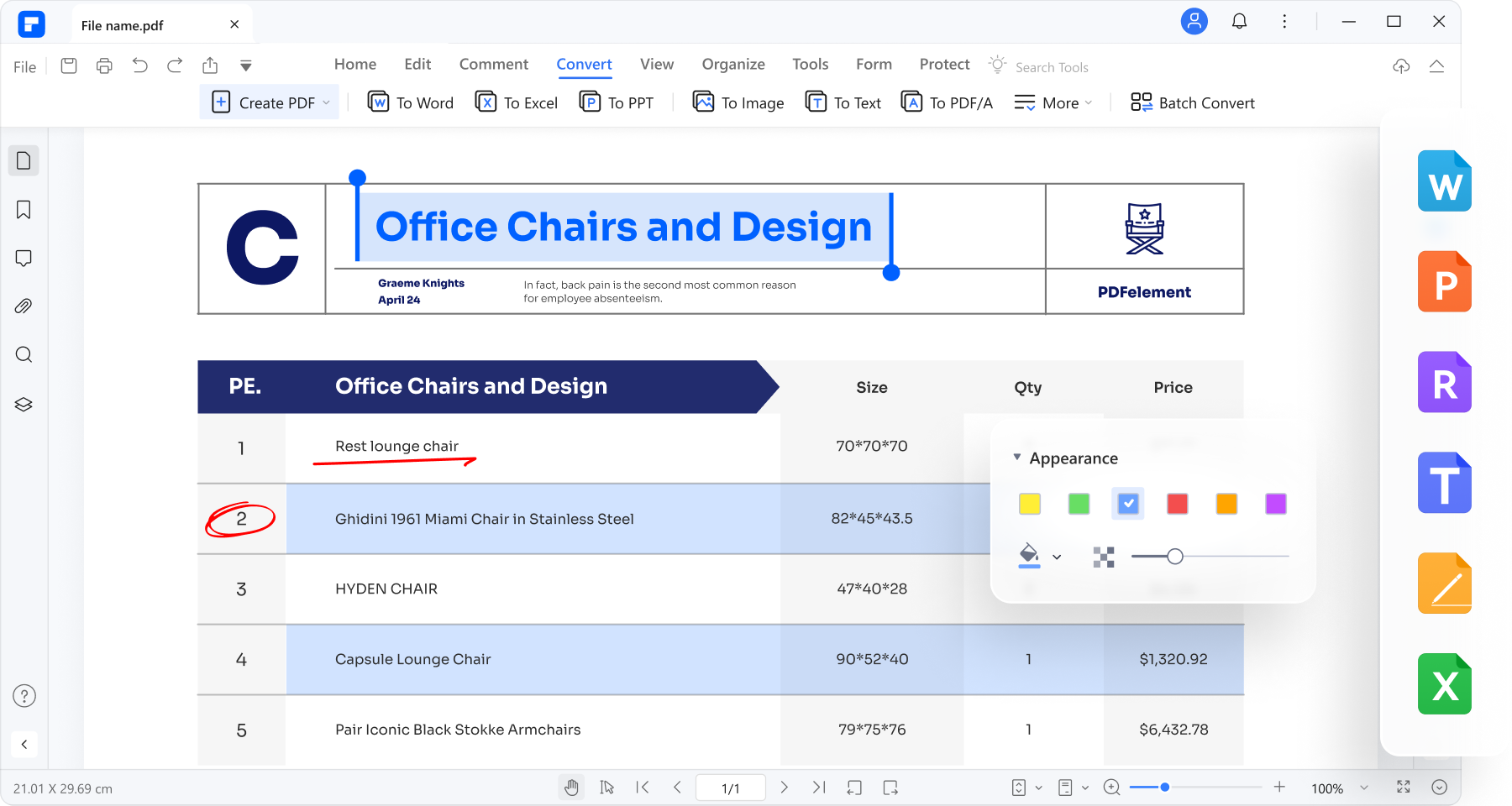
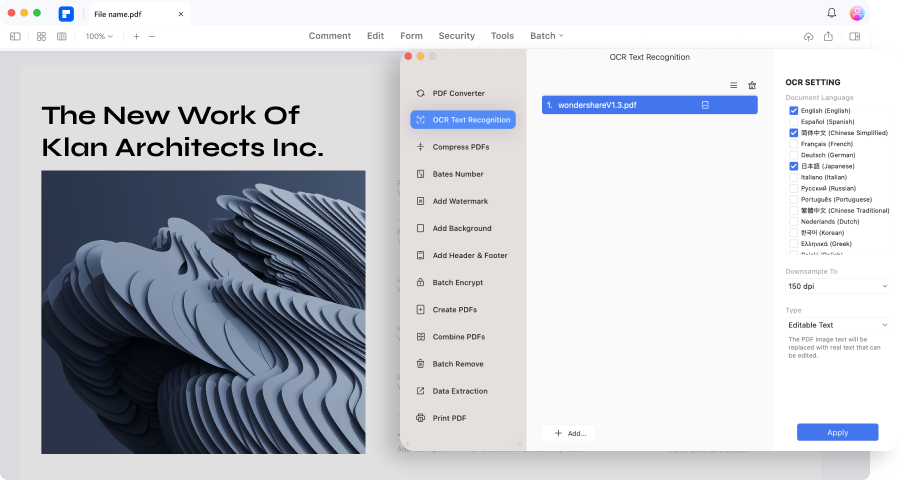
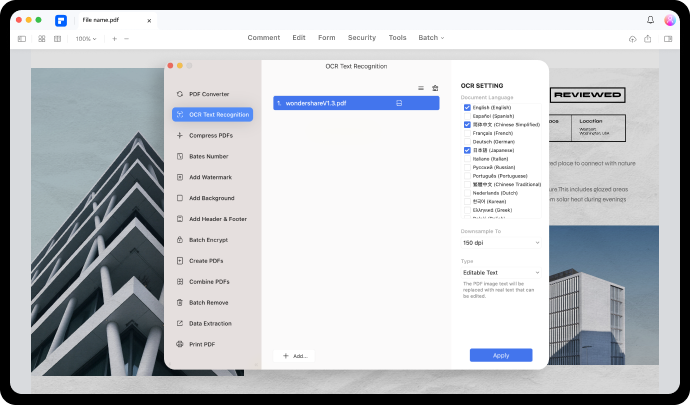
스캔한 PDF 문서의 텍스트를 편집합니다.
OCR 기능을 사용하면 스캔한 PDF 및 이미지 기반 PDF를 Word 문서를 편집하는 것처럼 쉽게 편집할 수 있습니다. 새로 추가된 텍스트는 스캔한 PDF 및 이미지의 기존 글꼴과 동기화할 수 있습니다.
스캔한 PDF 문서의 텍스트를 편집합니다.
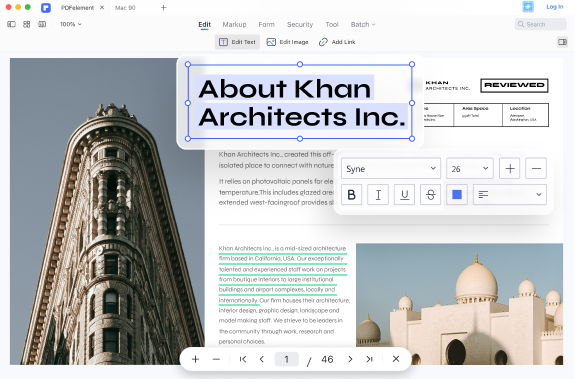
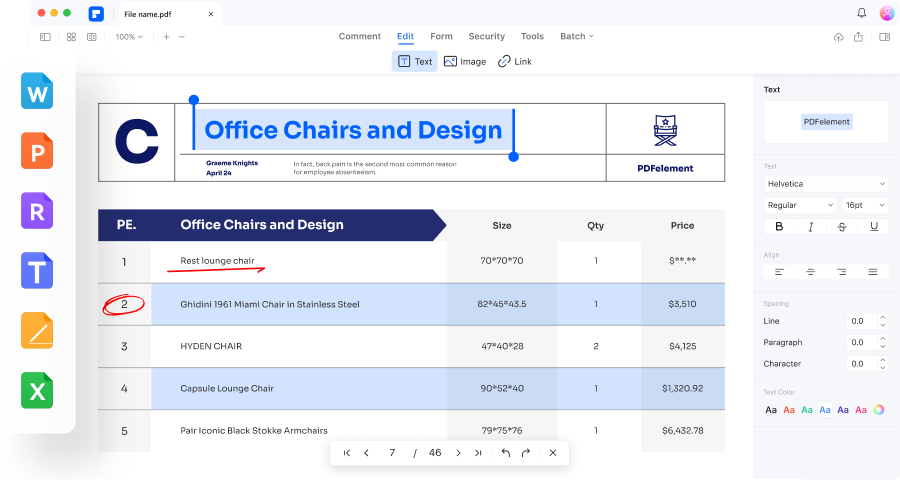
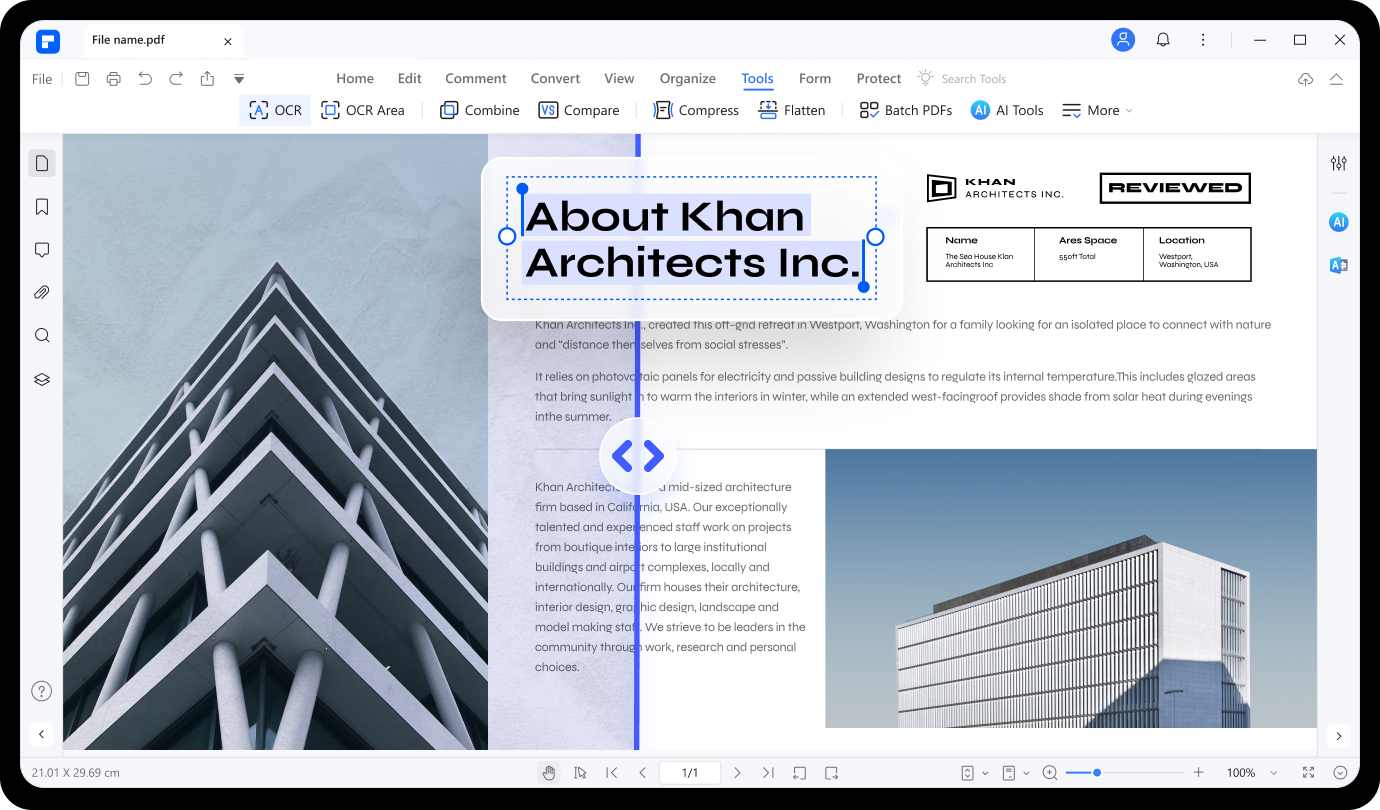
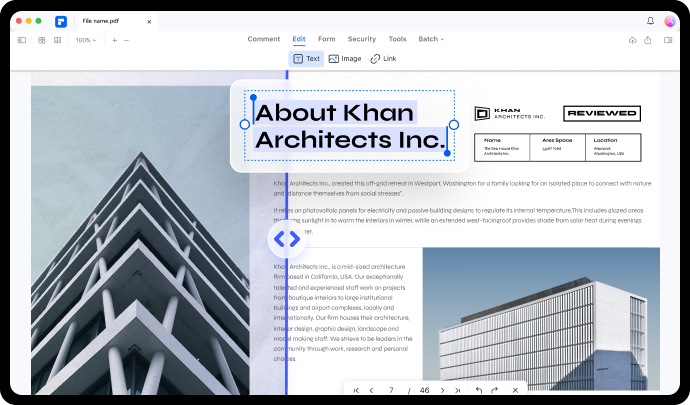
이미지를 편집 가능한 Microsoft Office 형식으로 변환합니다.
스캔한 PDF 및 이미지 기반 PDF를 Microsoft Office 형식, 페이지 또는 일반 텍스트 문서(TXT 파일)와 같은 편집,선택 및 검색 가능한 다양한 형식으로 변환합니다.
이미지를 편집 가능한 Microsoft Office 형식으로 변환합니다.
스캔한 PDF에서
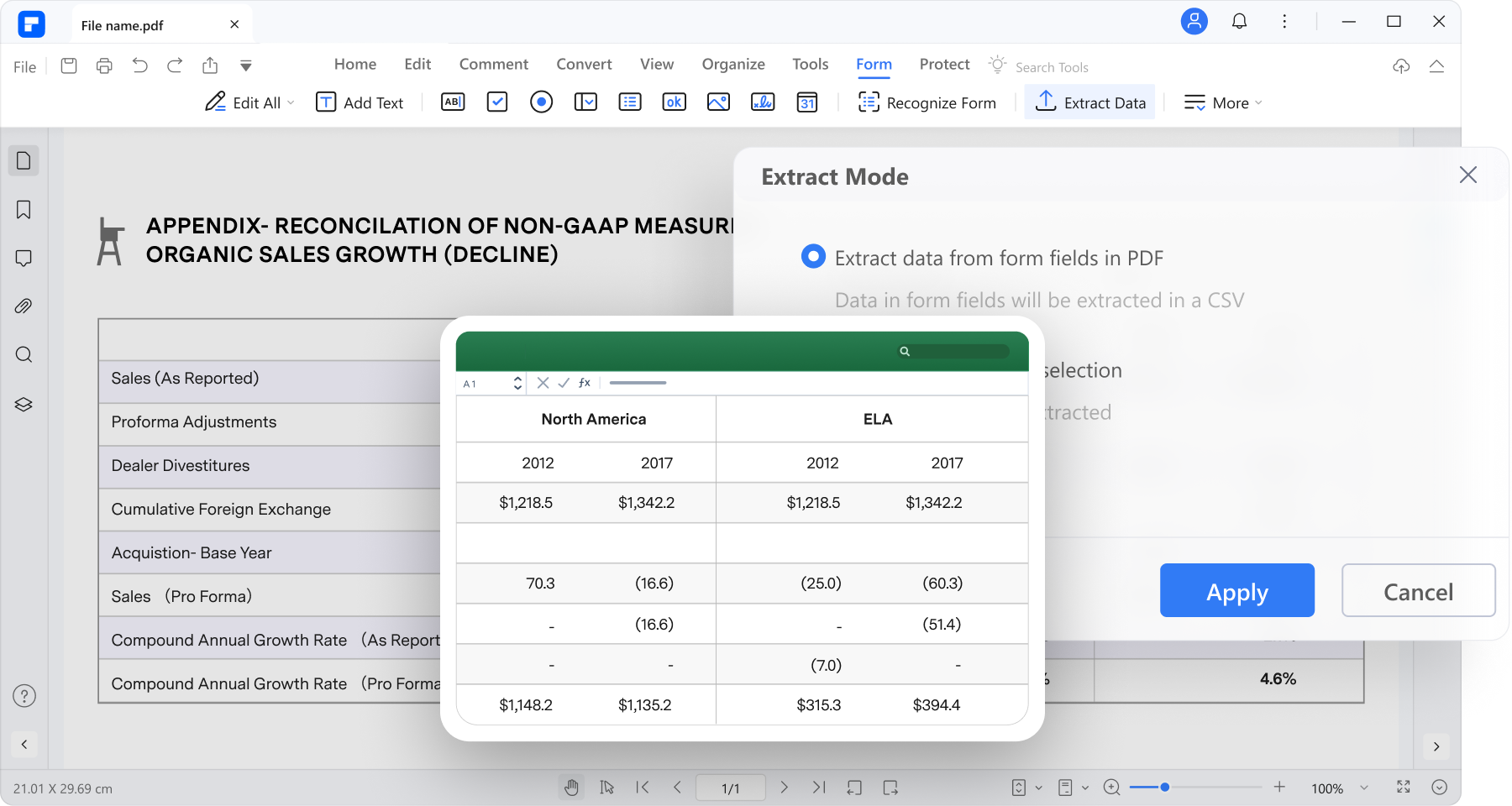
데이터 추출하기
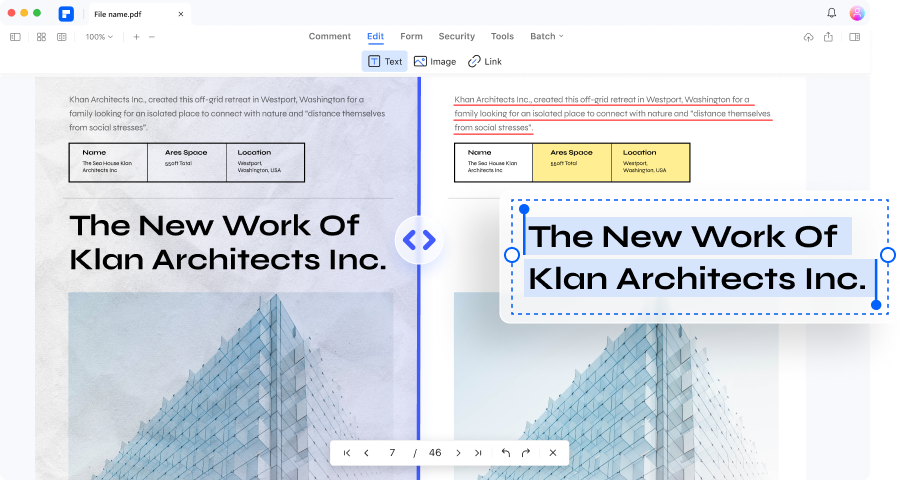
더 이상 수동으로 데이터 입력할 필요가 없습니다. PDFelement를 사용하면 스캔한 PDF 및 이미지 기반 PDF에서 선택한 영역의 데이터를 추출하거나 OCR을 수행한 후 PDF의 필드에서 데이터를 추출할 수 있습니다.
스캔한 PDF에서
데이터 추출하기
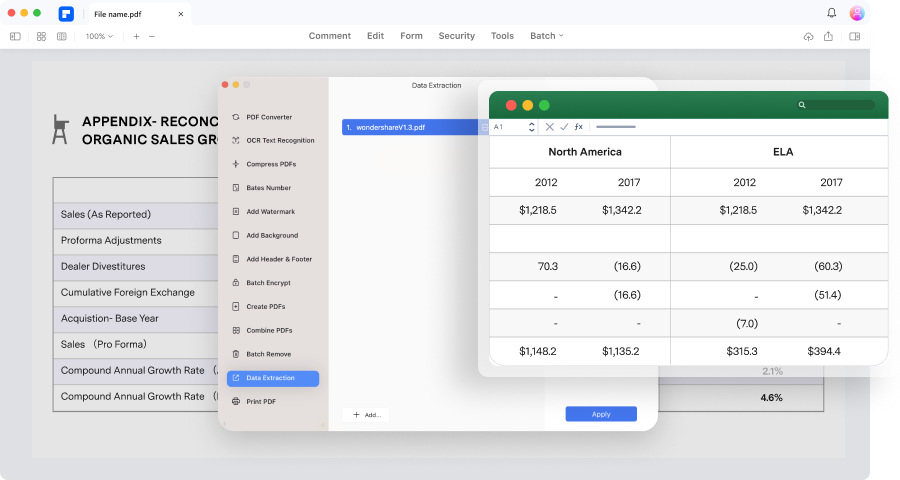
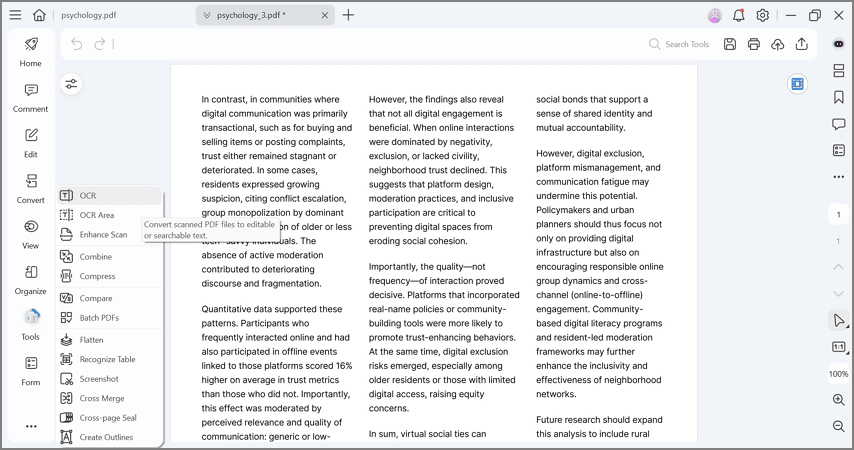
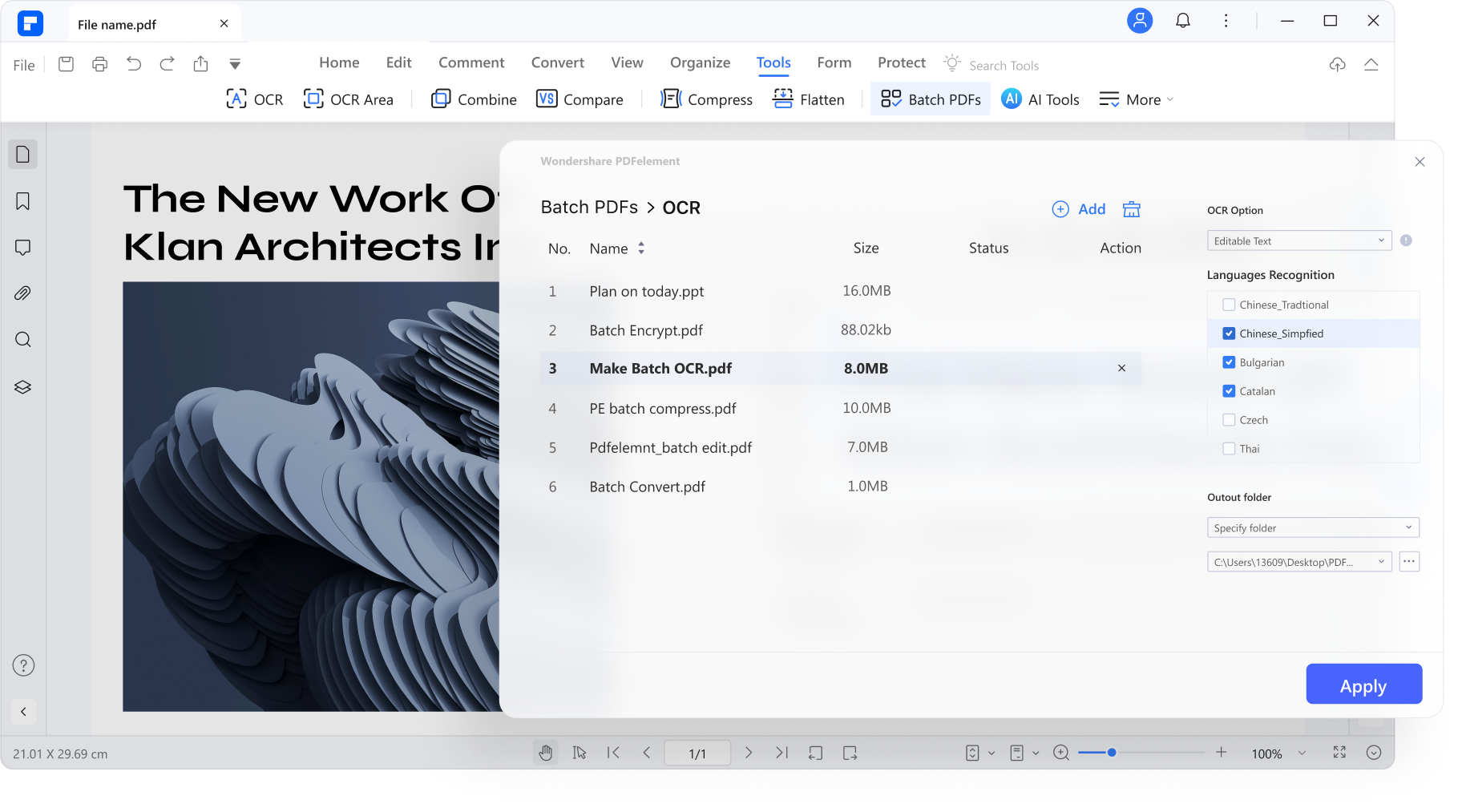
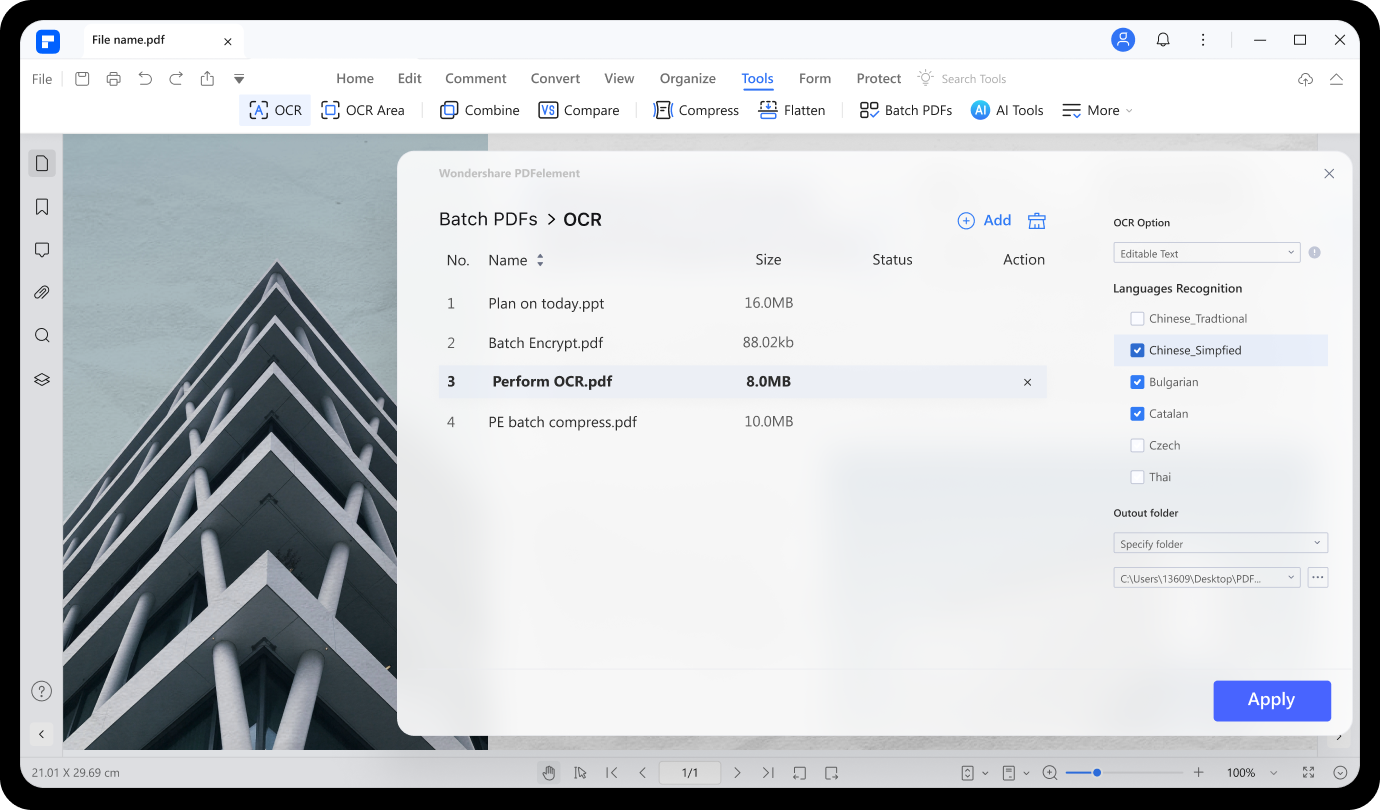
여러 스캔 파일을 몇 분 안에 편집 가능한 파일로 변환합니다.
스캔한 문서와 이미지만 있는 대용량 PDF 파일에서 데이터를 검색해야 하는 경우 어떻게 하시나요? PDFelement의 일괄 OCR 기능을 사용하면 스캔한 여러 PDF 또는 이미지 기반 PDF 파일을 번거로움 없이 편집 및 검색 가능한 PDF 파일로 변환할 수 있습니다.
여러 스캔 파일을 몇 분 안에 편집 가능한 파일로 변환합니다.
업무효율 향상을 위한 스마트 OCR 리더

OCR PDF 기능을 사용하여 PDF 를 검색 가능한 파일로 변환하고 다양한 종류의 데이터를 관리하고 분류하기 위해 Office 편집 가능한 형식으로 저장합니다.

다운로드한 웹 페이지를 OCR로 일괄 변환하여 검색 가능하게 만들고 데이터를 추출하는데 아주 편리합니다.

이미지형식으로된 학술지를 읽고 PDFelement OCR 기능을 사용하여 문장을 강조 표시하고 기사에서 키워드를 검색하여 효율성이 아주 높아졌습니다
스캔한 PDF를 편집 가능한 PDF로 변환하는 방법은 무엇인가요?



PDF 일괄처리에 대한 FAQ
-
OCR이란 무엇입니까?
OCR(Optical Character Recognition)은 이미지 및 스캔 문서의 텍스트를 인식하기 위한 레이아웃 스캐너입니다. 캡션이 있는 이미지를 읽을 수 있고 검색 가능한 데이터로 변환할 수 있습니다. 물론 타자, 인쇄 또는 손으로 쓴 문서가 포함됩니다. 대부분의 조직에서는 OCR을 사용하여 ID, 여권, 송장 등과 같은 문서에서 편집 가능한 텍스트를 스캔, 분석 및 추출합니다.
-
PDF를 검색 가능하게 만드는 방법은 무엇인가요?
원더쉐어 PDFelement를 사용하여 PDF 파일을 검색 및 편집 가능한 텍스트로 빠르고 쉽게 변환할 수 있습니다. 그 방법은 다음과 같습니다:
1단계. Windows 또는 macOS 컴퓨터에 PDFelement를 설치하고 실행합니다.
2단계. OCR PDF를 선택하고 PDF 파일을 업로드합니다. 스캔 옵션을 "이미지에서 검색 가능한 텍스트로 스캔"으로 설정하는 팝업 창이 표시됩니다. 적용을 클릭하기 전에 페이지 범위 및 언어 인식을 선택할 수도 있습니다.
3단계. PDFelement는 PDF 문서를 스캔하고 분석합니다. 이제 더 많은 텍스트, 이미지 오버레이, 웹사이트 링크, 서명, 피드백 등으로 PDF 편집을 진행하십시오.
-
스캔한 PDF를 Word로 어떻게 변환합니까?
PDFelement를 사용하면 스캔한 PDF를 편집 가능한 Word 파일로 변환할 수 있습니다. 단계는 다음과 같습니다.
1단계. PDFelement를 실행한 다음 OCR PDF를 클릭하여 PDF를 업로드하고 OCR을 수행합니다.
2단계. PDF 파일을 스캔하고 편집한 후 상단 메뉴 표시줄에서 변환 버튼을 클릭합니다.
3단계. 파일 이름을 지정하고 대상 경로를 선택한 다음 PDF로 변환합니다.
-
무료 OCR 소프트웨어가 있나요?
현재 많은 온라인 OCR 프로그램이 있으나 대부분은 무료가 아닙니다. 고품질의 OCR 서비스를 찾고 있다면 Wondershare PDFelement를 설치하고 스캔한 이미지를 포함한 모든 PDF 파일을 인식하세요. PDFelement OCR 기능은 인식 정확도가 업계에서 최고로 높습니다.